









Apparus dès 2018 et popularisés depuis 2021, les Reverse ETL font partie d'une nouvelle famille de software. Ils redéfinissent la façon dont les entreprises peuvent tirer parti de leurs données.
Nos clients rapportent une hausse de leur taux de conversion de 25% grâce à cette solution.
Les informations à retenir :
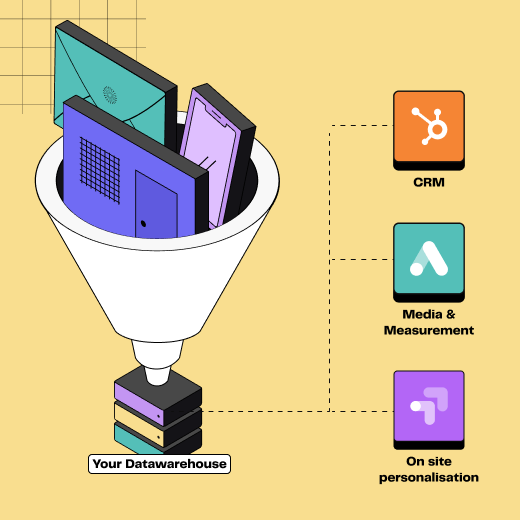
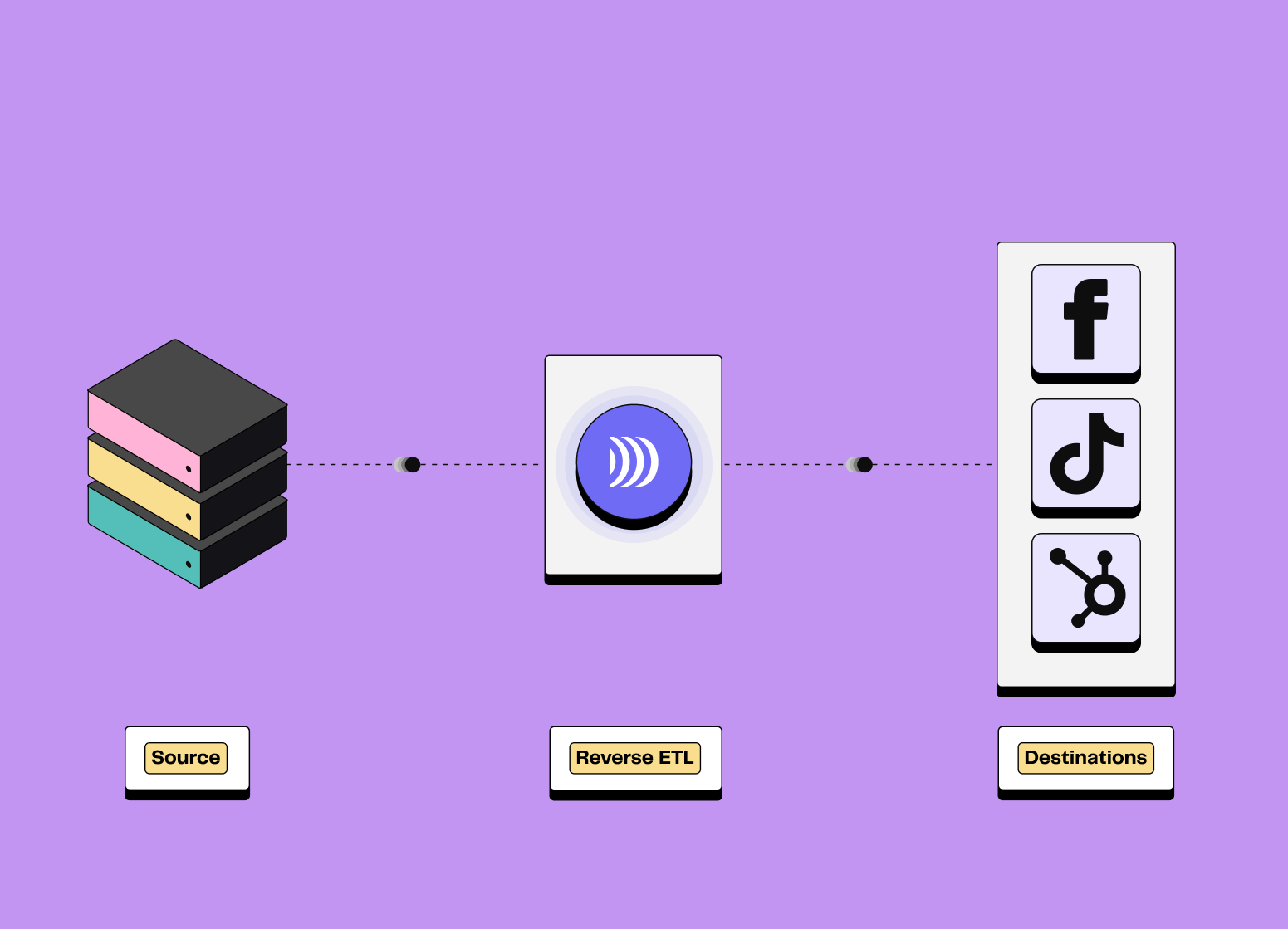
Le Reverse ETL permet de transférer des données depuis un data warehouse vers des outils métier (CRM, plateformes publicitaires, service client etc).
C’est le processus inversé de l’ETL (Extract, Transform, Load), qui consiste à extraire des données, les transformer et les centraliser les données dans un entrepôt.
Les Reverse ETL améliorent les campagnes marketing et fournissent des insights en temps réel aux équipes commerciales et de support.
Ils permettent de synchroniser les données clients, segmenter les audiences et automatiser les workflows dans une approche data-driven.
🤔 Dans cet article, vous apprendrez ce que sont les Reverse ETL et comment ils peuvent vous faire gagner du temps et de l'argent. Découvrez leur fonctionnement et les critères pour choisir la solution la plus adaptée à vos besoins.
Qu'est-ce que l'ETL ?
Pour comprendre ce qu'est un Reverse ETL, il faut déjà saisir ce qu'est un ETL (Extract, Transform, Load). Le processus d'Extraction, Transformation et Chargement consiste à extraire des données de différentes sources, à les transformer en modèles exploitables, puis à les charger dans un data warehouse (dwh).
De nombreux outils d'ETL existent, comme Fivetran, AWS Glue ou encore Hevo.


Illustration du processus Extract Transform Load
💡 L’ETL se distingue de l’ELT. Plus qu’un simple échange de lettres, l’ETL et l’ELT se différencient principalement par le moment et l’endroit où les données sont transformées.
Dans le cas du processus ETL, la donnée brute est transformée avant d'être transmise au data warehouse.
Au contraire, le processus ELT implique de charger de la donnée brute dans le data warehouse puis de la transformer.
Depuis les années 2010, d'énormes investissements ont été réalisés dans le stockage de données cloud. Et les entreprises continuent à investir. Une étude récente d’IDC* prévoit un taux de croissance annuel de 20% des dépenses en infrastructure cloud.
Pourquoi ? Plusieurs raisons peuvent être avancées :
Évolutivité : Les data warehouses cloud s'adaptent aux besoins des entreprises et évoluent avec l'utilisation qui en est faite.
Rentabilité : Le modèle de paiement à l'utilisation réduit les dépenses. Les coûts de stockage sont réduits.
Flexibilité et agilité : Les data warehouses cloud permettent un déploiement rapide et une intégration simple avec les outils existants. Ils sont faciles à utiliser et permettent le traitement de données massives.
Sécurité : Toutes les solutions adoptent des mesures robustes, disposent de certifications de conformité et assurent le chiffrement des données.
Avec des réglementations de plus en plus strictes sur les données first-party, les data warehouses cloud permettent de reprendre le contrôle de vos données pour répondre aux exigences des clients.
Pourtant, la plupart de ces données centralisées dans des data warehouses sont aujourd'hui sous-utilisées. En 2021, seules 9% des entreprises optimisaient leurs opérations marketing sur tous leurs canaux d'acquisition et tout au long du parcours client pour atteindre leurs résultats commerciaux.
En effet, une fois que les données résident dans le data warehouse, les récupérer et les utiliser dans les outils des équipes métiers relève du défi. C'est là que les Reverse ETL entrent en jeu…
Qu'est-ce que le Reverse ETL ?
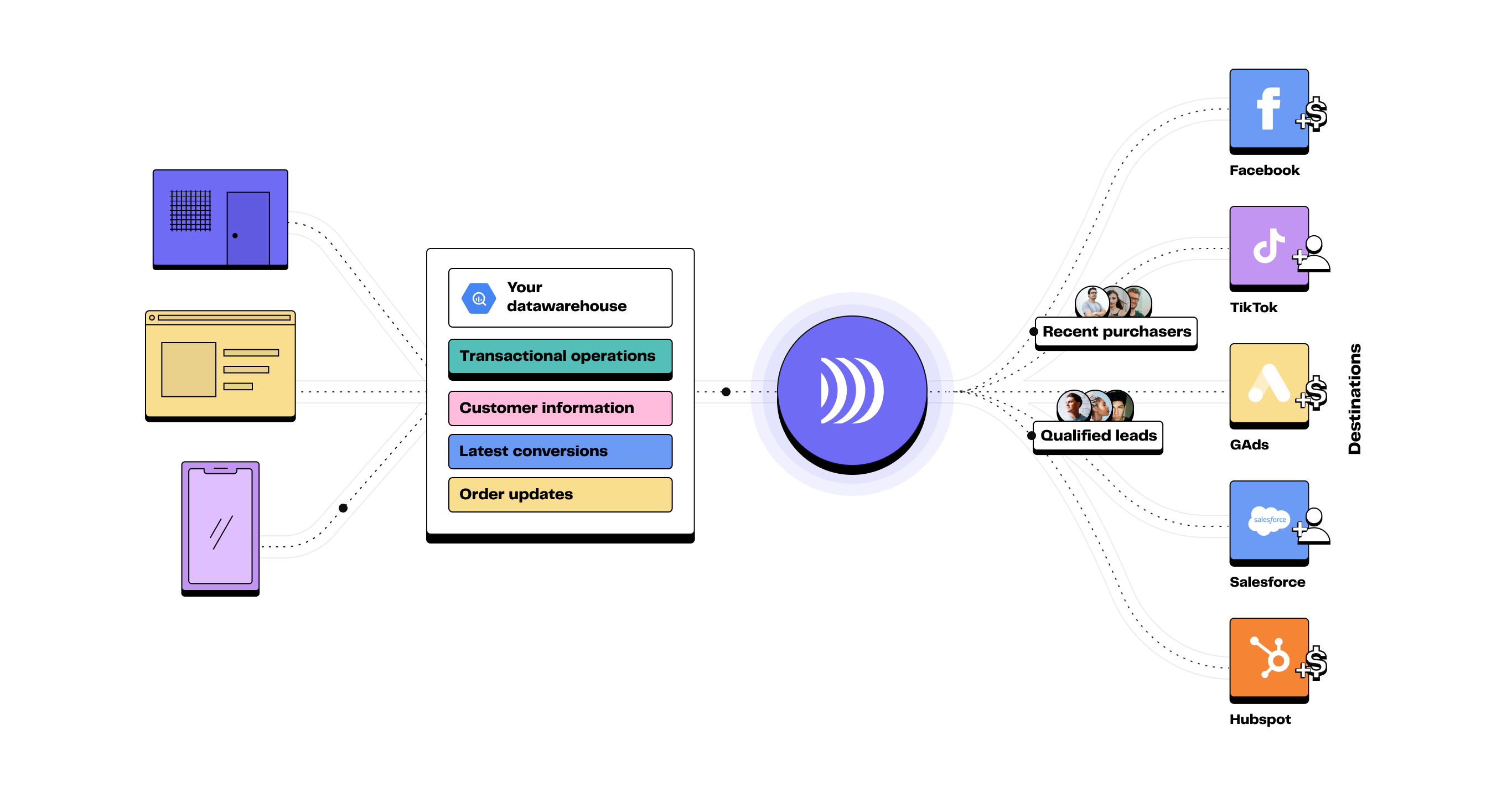
Le Reverse ETL est un processus qui permet de synchroniser les données stockées dans un data warehouse avec des outils métier tels que les CRM, plateformes publicitaires et solutions d'automatisation.
Il s'intègre dans une stratégie data-driven en transformant les données centralisées en actions concrètes pour les équipes opérationnelles.
Les données peuvent être transformées et exploitées en temps réel en les envoyant directement aux applications opérationnelles : CRM, plateformes de marketing automation, outils de support client.
Généralement les équipes métiers doivent créer des tickets auprès des équipes IT pour alimenter leurs outils en données. Ce process entraîne des délais importants. Les Reverse ETL font le lien entre les équipes data et les équipes opérationnelles.

Illustration du processus Reverse ETL
Les Reverse ETL ne sont pas seulement des pipelines. Au-delà du transfert de données, ils permettent aux organisations de modéliser et de transformer les données avant de les envoyer aux outils métiers.
Le nettoyage, la segmentation et la création d’audiences rendent les données plus utiles et pertinentes pour les systèmes opérationnels.
👉🏼 En résumé, les Reverse ETL permettent la synchronisation de la donnée entre différents systèmes et applicatifs pour assurer précision et cohérence.
Pour en savoir plus sur les Reverse ETL, téléchargez notre guide complet.
👇
Le guide ultime des Reverse ETL
Tout ce que vous devez savoir sur les Reverse ETL et comprendre pour bien choisir la votre
Principes et fonctionnement
Les Reverse ETL fonctionnent en exécutant des requêtes dans votre data warehouse. Ils transfèrent ensuite les résultats aux outils sélectionnés (que ce soit une destination marketing, un CRM ou une plateforme d'automatisation).
ETL vs Reverse ETL
La principale différence entre l'ETL et le Reverse ETL réside dans le sens du flux de données. En effet, l'ETL extrait les données des systèmes sources, les transforme en fonction des besoins d'analyse et les charge dans un data warehouse. Le Reverse ETL, quant à lui, transfère les données d'un data warehouse vers des outils métiers.
Comme son nom l’indique, le Reverse ETL effectue donc le cheminement inverse de l’ETL. Il permet de transférer des données centralisées dans le data warehouse vers tous les applicatifs de l'entreprise : marketing, ventes, service client etc.
Composants d’un Reverse ETL
Il y a 5 composants principaux à un Reverse ETL :
Source : Fait référence au data warehouse (ou data lake) où toutes les données dont vous souhaitez tirer de la valeur sont stockées. Snowflake ou Google BigQuery figurent parmi les data warehouses les plus courants.
Modèles : Le modèle de données sert de représentation de vos données. Il définit les données auxquelles vos équipes métier ont accès. Il est généralement conçu et maintenu par un expert en data, familier avec le data warehouse. Une fois configuré, tout le monde peut l'utiliser facilement sans avoir à coder.
Segments : Un segment est un sous-ensemble du modèle de données. Par exemple, il est possible de créer un segment tel que "utilisateurs résidant en Europe" ou un segment de "utilisateurs ayant dépensé plus de 100€", à partir de l'entité Clients (définie dans le modèle).
Ces segments peuvent être fait à partir de requêtes SQL ou d'un segment builder no-code, comme le propose DinMo.
Syncs : Cela fait référence au mécanisme de synchronisation des données d'un segment avec un outil en aval selon un calendrier défini. Vous pouvez configurer plusieurs synchronisations à partir du même modèle de données vers différentes destinations.
Cela garantit que toutes les équipes de votre entreprise travaillent à partir de la même donnée (grâce à une source unique de vérité).
Destinations : Une destination fait référence à tout outil externe ou service vers lequel vous pouvez envoyer des données source.
C'est généralement là que les utilisateurs finaux (i.e. les équipes métier) accèdent et utilisent les données. Les destinations les plus courantes sont les plateformes publicitaires, les CRMs ou les plateformes d'automatisation marketing.


Composants principaux d'un Reverse ETL
Quels sont les avantages des Reverse ETL ?
Les Reverse ETL aident les entreprises à garantir que leurs données sont cohérentes et toujours à jour sur l'ensemble de leurs systèmes.
Les données sont en effet partagées entre les applications opérationnelles et l'ensemble des équipes au sein de votre entreprise. Elles ne restent pas silotées.
Avec ce type d'outil, vous pouvez obtenir :
Une vue à 360° de votre parcours client : L'équipe data se charge de rendre les données pertinentes, accessibles et prêtes à être utilisées dans le data warehouse. Par la suite, les équipes métier peuvent mener de manière autonome leurs analyses pour obtenir des informations pertinentes en temps réel. Ceci permet d'améliorer l'expérience client tout au long du parcours.
Une prise de décision rapide et basée sur les données : Des informations toujours à jour peuvent être chargées rapidement dans les systèmes opérationnels. Ceci garantit des données pertinentes et précises aux opérationnels.
Et leur offre plus de réactivité face aux changements du marché, demandes des clients et opportunités émergentes.
Des contenus et campagnes marketing plus personnalisés :
Le Reverse ETL est particulièrement utile pour la publicité. Les équipes marketing ont souvent besoin de segmenter les données pour diverses raisons, comme la création d'audiences similaires (lookalike), l'exclusion de certains groupes de clients des campagnes, ou le ciblage de "top" clients. Avec le Reverse ETL, toutes les audiences peuvent être gérées de manière centralisée et synchronisées avec les plateformes marketing.
Le Reverse ETL transmet des données first party, comme des attributs, des caractéristiques ou des métriques prédictives personnalisées, pour enrichir votre connaissance client dans votre CRM / logiciel de marketing du cycle de vie (par exemple Braze). Cela permet une personnalisation tout au long du parcours client.
Amélioration des opérations client :
Les outils des équipes commerciales sont enrichis avec des informations supplémentaires (utilisation du produit, préférences de canal, etc.).
Les équipes de support bénéficient également du Reverse ETL, car il permet de synchroniser en temps réel les informations client dans leur système. Ceci permet de prioriser les actions de support en fonction de l'utilisation du produit et de la valeur du contrat du client.
👉🏼 Beaucoup de cas d'usage sont possibles avec les Reverse ETL. Consultez notre article détaillé pour en avoir une idée complète ou écoutez le podcast Data Gen dans lequel nous sommes intervenus.
Quelles sont les solutions alternatives de synchronisation des données ?
Le transfert des données peut se faire de différentes manières :
Téléchargements manuels de fichiers csv / Excel
Pipelines personnalisées
Autres outils tels que iPaaS ou CDP.
Reverse ETL vs. iPaaS
Les Integration Platform as a Service (iPaaS - littéralement Plateforme d'intégration en tant que service) sont des plateformes qui connectent des applicatifs entre eux. Un déclencheur spécifique dans un outil entraîne une réponse spécifique dans un autre. Par exemple, une soumission de formulaire sur Typeform peut automatiquement créer un nouveau contact dans Hubspot.
Techniquement, les iPaaS peuvent connecter des applications via des API, ce qui facilite grandement la tâche pour des intégrations simples (point à point et sans dépendances).
La principale différence entre un Reverse ETL et l'iPaaS est que le Reverse ETL s'applique à envoyer de la donnée d'une source unique vers des destinations marketing. De son côté, l'iPaaS crée un flux bi-directionnel, en bougeant de la donnée d'un point A vers un point B.
Les iPaaS populaires sont des outils tels que Workato, Zapier ou Boomi.
Une iPaaS connecte simplement des systèmes un à un et présente plusieurs limitations :
Elle génère un réseau complexe de pipelines et de workflow qui ne sont pas évolutifs.
À mesure que les workflows deviennent complexes, les utilisateurs ont besoin de connaissances en matière d'API, ce qui annule l'avantage du "no code". Les équipes métier auront besoin d'aide de la part des équipes de données.
Elle n'est pas conçue pour les mises à jour en masse de gros volumes (ou est extrêmement coûteuse si vous vous y risquez).
Elle ne repose pas sur source unique de vérité et un profil unique pour un client (Customer 360) et peut donc entraîner des expériences client incohérentes.
Elle fonctionne comme une "boîte noire" et pose des problèmes de gouvernance et de qualité de la donnée.


iPaaS vs. Reverse ETL
Reverse ETL vs. CDP
Une Customer Data Platform (CDP) est une plateforme prête à l'emploi qui stocke et organise les données clients provenant de sources multiples afin de créer une source unique de vérité.
En tant que telle, une CDP traditionnelle est une alternative au data warehouse. Cependant, la CDP offre des fonctionnalités avancées en plus des objectifs de BI :
Préparation des données pour les cas d'usage métiers : segmentation, création d'agrégats, de scores client, etc.
Redistribution vers les applicatifs des équipes métiers
En résumé, la CDP combine les rôles d'un data warehouse et d'un Reverse ETL. La CDP offre donc plus de fonctionnalités qu'un Reverse ETL, mais ce dernier reste une brique essentielle de ce type de plateforme.
Pourtant, depuis une quinzaine d'années que les CDP existent, l'écosystème a considérablement évolué. Seulement 1% des entreprises pensent que les CDP répondent à leurs besoins actuels et futurs.
Une CDP intégrée présente en effet plusieurs défauts :
Rigidité : La CDP impose des modèles de données rigides et limite la création de modèles personnalisés.
Prix : La CDP packagée est une solution coûteuse, inaccessible à la plupart des petites et moyennes entreprises.
Confidentialité et sécurité : Comme elle stocke les données, la CDP traditionnelle est une solution moins sûre et soulève une question de contrôle des données.
Dans leur forme traditionnelle, les CDP sont moins attrayantes. Les entreprises se tournent aujourd’hui vers les CDP composables, ou modulaires.
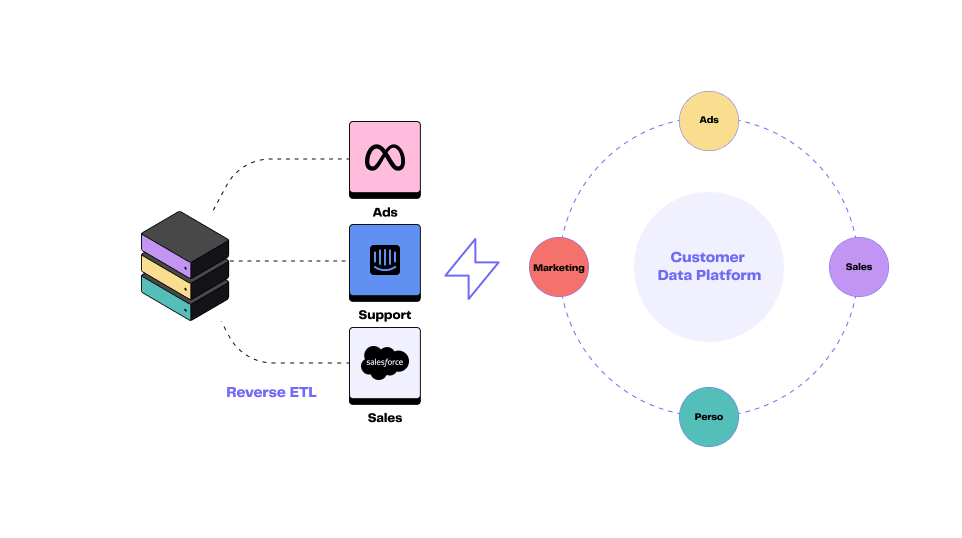
Le processus de Reverse ETL fait partie de la CDP composable, qui s'appuie sur un data warehouse cloud et active ces données vers de nombreuses destinations différentes.


CDP vs. Reverse ETL
Construire ou acheter un Reverse ETL ?
À ce stade, vous êtes probablement déjà convaincu de la valeur du Reverse ETL. Cependant, vous pourriez vous encore demander : et si mon entreprise créait ses propres connecteurs API entre mon data warehouse et les systèmes opérationnels (comme Meta, Salesforce, Brevo, etc.) ?
En apparence, cela semble réalisable. Supposons que quelqu'un de l'équipe Customer Success veuille afficher la probabilité de churn calculé dans le data warehouse dans Intercom. Un ingénieur pourrait consulter l'API d'Intercom, comprendre les points d'accès pertinents et créer une intégration personnalisée. Cela semble assez simple.
Mais que se passe-t-il lorsque les méthodes prédictives changent, que l'équipe Support veut afficher plus d'informations dans Intercom ou passer d'Intercom à Zendesk ?
Dans ces cas, les ingénieurs devraient construire et maintenir une autre intégration personnalisée. C'est là que les problèmes apparaissent :
La création manuelle de connecteurs API peut prendre des jours ou des semaines. Chaque intégration tierce vient avec ses spécificités et sa technicité, ce qui complique encore les choses.
Les points d'accès API ne peuvent souvent pas gérer le transfert de données en temps réel, ce qui signifie que vous pourriez rapidement atteindre vos limites.
Votre équipe devrait constamment entretenir ces connecteurs pour s'adapter aux changements dans les applicatifs sous-jacents.
Il y a donc peu de valeur à ce que votre équipe data construise et entretienne des pipelines pour le Reverse ETL, même si cela semble moins cher que de payer pour une solution.
⚠️ Lors du choix d'une plateforme Reverse ETL, assurez-vous de vérifier les critères importants pour votre entreprise : que la solution soit en SaaS ou "on-premise", pour quels utilisateurs la plateforme est destinée (équipes techniques ou métiers) et les intégrations proposées.
Critères pour bien choisir sa solution
Comparaison des outils présents sur le marché
A noter qu'il existe plusieurs catégories de Reverse ETL :
Les outils d'intégrations, qui se concentrent sur la simplification du mouvement des données pour les équipes data.
Les outils Reverse ETL généralistes, qui prennent en charge l'intégration de n'importe quelle source vers n'importe quelle destination, mais dédiés aux équipes data.
Les outils Reverse ETL spécialisés, qui mettent l'accent sur la possibilité pour les équipes métiers d'utiliser les données de manière plus efficace, sans dépendre des équipes data.
🌟 Plusieurs acteurs se positionnent sur le marché et dans les différentes catégories. Nous avons écrit un benchmark des Reverse ETL pour vous aider à choisir une solution adaptée à votre entreprise.


Comparaison des catégories de Reverse ETL
Chez DinMo, nous ne répondons pas seulement aux besoins des équipes data. Nous offrons aux équipes métier un outil qu'elles peuvent parfaitement utiliser sans avoir besoin d'un ingénieur.
DinMo est la seule solution de Reverse ETL facile à utiliser pour les équipes non techniques. Nous combinons l'expérience utilisateur sans code des meilleurs CDP traditionnelles et la simplicité et la flexibilité des Reverse ETL.
Nous avons choisi la Reverse ETL DinMo parce que la solution était simple à mettre en place et surtout à utiliser. En 1 heure, tout était configuré. Nous avons pu construire nous mêmes nos segments sans passer par l'équipe data, et les utiliser directement dans nos outils d'acquisition.
Sylvain Seng Bandith, Lead Perfomance @Ankorstore
Si vous voulez en discuter avec nous👇
Passez de Census ou Hightouch à DinMo
Le tout en quelques minutes, avec un accompagnement personnalisé de notre équipe. A vous les fonctionnalités no-code sans coûts supplémentaires !
Les critères de choix
Avant d'acheter un Reverse ETL ou d'essayer de le construire vous-même, il est important de connaître les principales fonctionnalités à rechercher :
Compatibilité avec vos destinations préférées : La pertinence d'un outil Reverse ETL dépend largement de sa compatibilité avec vos destinations d’intérêt. Lors du choix d'un outil, pensez à vos besoins actuels et futurs. Certaines destinations ne sont pas encore disponibles sur la plupart des éditeurs. Par exemple, Batch est uniquement disponible avec DinMo.


Service de sync robuste : La synchronisation des données est un aspect central des outils Reverse ETL. Elle doit être rapide et fiable.
Choisissez un fournisseur qui utilise une approche “différentielle” pour la synchronisation des données. Cette approche n'envoie que les données nouvelles ou mises à jour. Cela peut économiser du temps et de l'argent.
Observabilité : Un outil Reverse ETL doit fournir des capacités d'observabilité pour une détection rapide des erreurs et doit aider à les résoudre. Des fonctionnalités d'alerte et des messages d'erreur clairs peuvent faire gagner du temps aux équipes techniques.
Sécurité : La protection des données est essentielle. Votre fournisseur doit répondre à toutes vos exigences pour garantir la sécurité de vos données sensibles.
Cela comprend par exemple la conformité avec des réglementations telles que RGPD/CCPA, des certifications comme SOC 2, des pratiques sécurisées de stockage des données, et des méthodes robustes de cryptage des données.
Facilité d'utilisation : Les outils Reverse ETL sont conçus pour simplifier la gestion des données. Ils doivent donc être faciles à utiliser.
Cherchez des fonctionnalités telles qu'un Segment Builder sans code, des interfaces utilisateurs intuitives, et des fonctionnalités de mappage de données simples qui ne nécessitent pas de connaissances techniques avancées (par exemple sur les APIs sous-jacentes).
Facilité de mise en œuvre : Un bon outil Reverse ETL doit être facile à configurer. Le modèle de données doit être suffisamment flexible pour répondre à vos besoins spécifiques, et toute personne ayant accès au data warehouse doit être capable de configurer l'outil facilement.
Support : Des experts en activation de données et des ressources (comme une documentation de qualité et des tutoriels) doivent être disponibles pour aider votre équipe à surmonter des obstacles éventuels.
👉🏼 DinMo est l'unique Reverse ETL du marché à avoir un support français.
Tarification transparente et évolutive : Le prix est un facteur important à prendre en compte lors du choix d'un outil. Assurez-vous de comprendre la structure tarifaire de l'éditeur.
Pensez également à comment le coût pourrait évoluer avec votre utilisation. Même si les prix initiaux semblent raisonnables, ils peuvent rapidement augmenter avec l'augmentation de vos besoins. Il est donc important de choisir une solution qui peut évoluer avec vous.
Conclusion
Alors que les entreprises s'efforcent de réussir leur transformation digitale, les Reverse ETL apparaissent comme un outil clé pour libérer le véritable potentiel des données centralisées dans un data warehouse. En envoyant les données aux applications de l'entreprise, les Reverse ETL sont des outils de choix dans le Modern Data Stack. En comprenant ses fonctions et ses avantages, les organisations peuvent s'engager sur la voie royale d'une stratégie data-driven.
👉🏼 Si vous avez envie d'améliorer votre Data Stack en adoptant des outils de première classe et souhaitez investir dans une solution de Reverse ETL actionnable en quelques minutes, réservez une démo avec nous.
💡 Si vous voulez en savoir plus sur les Reverse ETL ou avez besoin d'aide sur des sujets d'activation de la donnée, n'hésitez pas à me contacter : alexandra@dinmo.com
*Source: IDC Worldwide Software and Public Cloud Services Spending Guide
FAQ
Quels sont les cas d'usage les plus courants pour un Reverse ETL ?
Quels sont les cas d'usage les plus courants pour un Reverse ETL ?
Le Reverse ETL permet de synchroniser des données depuis un data warehouse vers des outils opérationnels. Voici ses principaux cas d'usage :
- Marketing ciblé : Créer des audiences précises pour des campagnes personnalisées sur des plateformes publicitaires.
- Personnalisation client : Envoyer des données enrichies aux outils de marketing automation pour des interactions adaptées.
- Ventes optimisées : Prioriser les leads grâce à des données actualisées directement dans le CRM.
- Support client amélioré : Offrir des réponses plus rapides grâce à des informations consolid�ées.
Pour aller plus loin, découvrez comment les Reverse ETL sont utilisés en entreprise.
En termes d'usages, un iPaaS peut-il remplacer un Reverse ETL ?
En termes d'usages, un iPaaS peut-il remplacer un Reverse ETL ?
Un Reverse ETL et un iPaaS (Integration Platform as a Service) ont des objectifs différents :
- Le Reverse ETL transfère des données depuis un data warehouse vers des applicatifs métier (CRM, plateformes marketing). Il garantit la cohérence et la centralisation des données, grâce à une "source unique de vérité".
- L'iPaaS connecte des applications entre elles via des workflows automatisés. Par exemple, un formulaire Typeform peut automatiquement créer un contact dans Hubspot.
Le Reverse ETL est conçu pour des volumes importants et des mises à jour complexes. De son côté, l’iPaaS est limité à des flux point-à-point simples et manque souvent de scalabilité et de gouvernance des données.
Combien de temps faut-il pour implémenter un Reverse ETL ?
Combien de temps faut-il pour implémenter un Reverse ETL ?
Avec DinMo, l’implémentation d’un Reverse ETL est rapide et intuitive. En moins d’une heure, vous pouvez :
- Configurer vos connexions avec le data warehouse et vos outils métier (CRM, plateformes publicitaires, etc.).
- Créer des segments de données prêts à l’emploi, sans aucune compétence technique requise.
- Synchroniser vos données en temps réel avec vos applications, pour une mise en œuvre immédiate.
Grâce à sa simplicité et à son interface no-code, DinMo est l’une des solutions les plus rapides à adopter sur le marché, même pour des équipes non techniques.
Un Reverse ETL peut-il remplacer une CDP ?
Un Reverse ETL peut-il remplacer une CDP ?
Un Reverse ETL ne remplace pas une CDP traditionnelle, qui stocke, analyse et gère les données clients dans une plateforme dédiée. Cependant, le processus de Reverse ETL, en tant que pipeline de données, est utilisé dans toutes les Customer Data Platforms.
Le Reverse ETL est également une brique essentielle des CDP composables, une approche qui combine les avantages d’un data warehouse et d’une activation des données sur mesure. En effet, il est possible de construire sa propre CDP Composable en exploitant le référentiel client de son data warehouse et un outil de Reverse ETL pour permettre l’envoi de données segmentées aux outils marketing. Plutôt que de fonctionner comme une entité distincte, la CDP composable s'intègre de manière transparente à n'importe quel environnement technique.
Les avantages d’une CDP Composable :
- Flexibilité : contrairement aux modèles rigides des CDP packagées, la CDP Composable s’appuie sur le modèle du data warehouse déjà en place dans l’entreprise. Le Reverse ETL peut ensuite transformer ces données pour répondre aux attentes techniques (API) des différentes outils marketing.
- Coût optimisé : cous n’êtes pas limité par les fonctionnalités pré-packagées et coûteuses d’une CDP. Vous choisissez les outils (data warehouse, Reverse ETL, outil de BI, etc.) en fonction de vos besoins.
- Sécurité renforcée : les données restent dans votre data warehouse, ce qui évite les duplications et offre un meilleur contrôle en termes de confidentialité et de conformité (RGPD, CCPA).